Posted by GUPTA, Gagan Published: April 27, 2020
|
Enjoy listening to this Blog while you are working with something else !
What is machine learning ?
Let's face the truth; machines do not learn. Yes, here I said it.
What a typical "learning machine" does, is finding a mathematical formula, which, when applied to a collection of inputs (called 'training data'), produces the desired outputs. This is not learning. Because, if you start distorting the inputs, outputs will be completely different, if not wrong. This is not how "learning" works in animals / humans. Today, even the best of the AI software can not tell a distinction between a cat and dog of similar size, with 100% accuracy, 100% of the times. A 3 year old child has a much higher chance of beating the AI software here.
you see; artificial intelligence is not intelligence, machine learning is not learning.
Its hard to define, and even harder to agree on a single definition of machine learning. IBM coined the term, back in 1959.
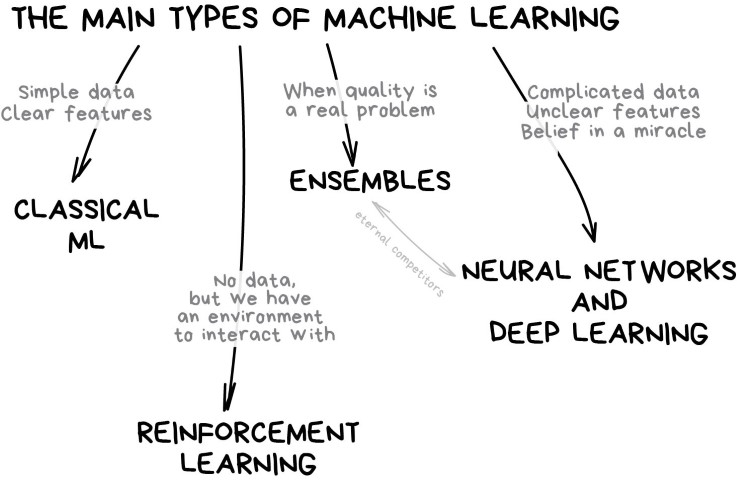
Machine learning is a subfield of computer science that is concerned with building "algorithms" which, to be useful, rely on a collection of examples of some phenomenon. This Learning can be supervised, semi-supervised, unsupervised and reinforcement. I will not go deep into all these different jargons here.
Our On-Premise Corporate Classroom Training is designed for your immediate training needs
Building blocks of any learning algorithm
Any learning algorithm has 3 building blocks:
1. a loss function
2. an optimization criterion
3. an optimization routine
Decision Tree learning and kNN are the oldest machine learning algorithms. Both were developed without a optimization criterion. Today, you often encounter gradient descent or stochastic gradient descent. Its important to understand them if you want to have any understanding of machine learning. Again, this blog is not the right place to explain this here. I need a much bigger platform.
Now the good thing. If you work or are going to work as machine learning engineers, you usually do not implement an algorithm yourself. Its all already written and made available for you to use through libraries. Most of these libraries are open source. The most frequent and popular library is scikit-learn. Its written in Python and C. Always remember, all these algorithm works only on numeric data only. If your data is not numerical, with some magic wand, somehow it must be converted to numerical equivalents. Scikit is documented well.
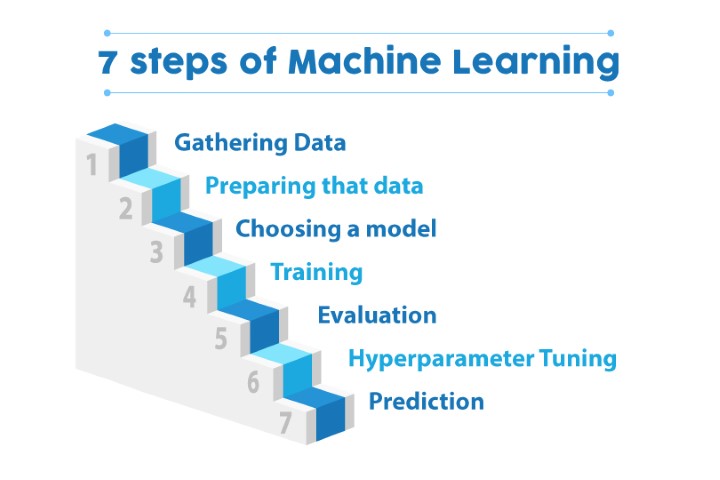
In machine learning, everything starts from a Dataset. Data is generally available in raw format. The problem of transforming raw data into data set is called Feature Engineering. Its a labor intensive process. This requires a lot of creativity and domain expertise from a Data Analyst.
One-hot encoding, Normalization, Standardization, Bucketing are some of the tools in your hands here.
When this is done; next step is the most crucial and complex. Choosing the machine learning algorithm. Remember, very often, you need to explain your model to a non-technical audience. Here is the diagram, scikit has for you to help here.
Strategically, you divide your data set in three blocks:
1. training set
2. validation set
3. test set
There are many strategies here to divide your data; 70%/15%/15%; 95%/2.5%/2.5%. There is no maths formula here. This is all domain and problem specific. How much data you have at hand ? Bias / over-fitting / under-fitting; one change their strategy as one moves forward. Regularization is a tool you might use here often.
Regularization is an umbrella-term that encompasses methods that force the learning algorithm to build a less complex model. In practice, that often leads to slightly higher bias but significantly reduces the variance. This problem is known in the literature as the bias-variance trade-off.
Two most widely used regularizations are L1 and L2.
Our On-Premise Corporate Classroom Training is designed for your immediate training needs
Neural Networks and Optimizations of machine learning algorithms
Any discussion on machine learning is incomplete without covering Neural networks. At the bottom, Neural networks are basically logistic regression, just a bit complex for human brain to comprehend. Just kidding !
A shallow learning algorithm learns the parameters of the model directly from the features of the training examples. Most supervised learning algorithms are shallow. The notorious exceptions are neural network learning algorithms, specifically those that build neural networks with more than one layer between input and output. Such neural networks are called deep neural networks. In deep neural network learning (or, simply, deep learning), contrary to shallow learning, most model parameters are learned not directly from the features of the training examples, but from the outputs of the preceding layers.
In neural network training, one challenging aspect is to convert your data into the input the network can work with.
Some optimization tips:
1. In the big data era, scientists often look for O(logN) algorithms.
2. From a practical standpoint, when you implement your algorithm, you should avoid using loops whenever possible.
3. Try multiprocessing, where ever possible. one must be comfortable with strategies learned from Big Data world.
Support our effort by subscribing to our youtube channel. Update yourself with our latest videos on Data Science.
Looking forward to see you soon, till then Keep Learning !
Our On-Premise Corporate Classroom Training is designed for your immediate training needs