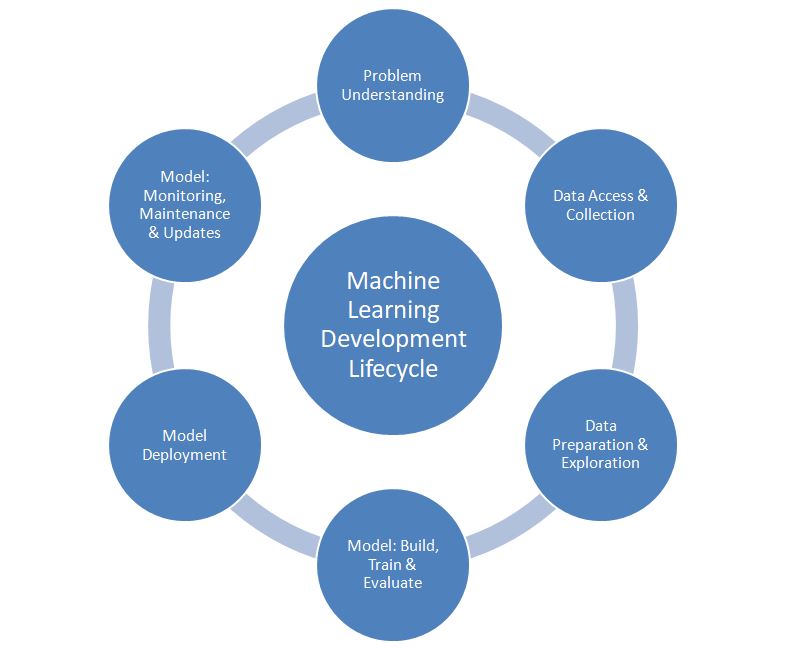
Machine Learning Development Life Cycle (MLDLC) is a multi stage (and underlying sub-stages) process acquired by the Teams to develop, train and serve the models using the Data Lakes that are involved in various applications so that the organization can take advantage of AL & ML algorithms to derive a practical business value. MLDLC is still evolving to be a standard model, often organization & projects customize the base model, based on their specific requirements.
It can be tempting to confuse MLDLC with SDLC. They are not the same thing. SDLC is a relatively deterministic process. In Data Science, we do not know the outputs beforehand. This risk is mitigated by following good practices and by defining success metrics, throughout the MLDLC process.
Machine learning is about data - no lie there. Machine learning is about development, manipulating data, and modeling. All of these separate parts together form a machine learning development life cycle.
Machine learning provides the benefits of power, speed, efficiency, and intelligence through learning without explicitly programming these into an application. It provides opportunities for improved performance, productivity, and robustness.
0-Problem Understanding
In Computer's we start to count from 0. Many organizations and projects choose to skip this step. Each project starts with a problem that one need to solve. Generating a ML-Model is not solution; solving the underlying problem is the solution. Many people seem to be under the assumption that an ML project is fairly straightforward if you have the data and computing resources necessary to train a model. They could not be more wrong. Moreover, just because the problem is defined in business terms, machine learning does not happen by itself. A lot of mountains must be moved.
Understand the business and the use case one is working with and define a proper problem statement. Asking the right questions to the business people to get required information plays a prominent role. Explain the problem in the terms of AI / ML project. If the business problem is not translated into a proper ML problem, then the final model is not deployable for the business use case. One might be able to generate the ML model successfully, but still far from solving the underlying business problem that needed attention.
Involve various stakeholders (Business User, Business SME's, Project Sponsor, Project Manager, BI analysts, DS engineers, Data Scientists, DBA). Run the feasibility report.
Have a system in place that provides data in real time or batch to a machine learning model and as a result of this model the system reacts and prescribe a new outcome. Simple enough!
1-Data Access And Collection
Once the problem is defined, The next step to a machine learning problem is accessing the data. While the end goal is a high-quality model, the lifeblood of training a good model is in the amount and quality of the data being passed into it.
Typically, data engineers will obtain the data for the business problems they are working on by querying the databases where their companies store their data. In addition, there is a lot of value in unstructured datasets that do not fit well into a relational database (e.g. logs, raw texts, images, videos, etc.). These datasets are heavily processed via Extract, Transform, Load (ETL) pipelines written by data engineers and data scientists. These datasets often reside in a data lake.
When data scientists do not have the data needed to solve their problems, they can get the data by scraping data from websites, purchasing data from data providers or collecting the data from surveys, clickstream data, sensors, cameras, etc. Another option to consider is buying data from third-party providers. Some of the datasets come from government organizations, some are from public companies and universities. Public datasets usually come along with annotations (when applicable), so you and your team can avoid doing the manual operations that take a significant amount of project time and costs.