Introduction
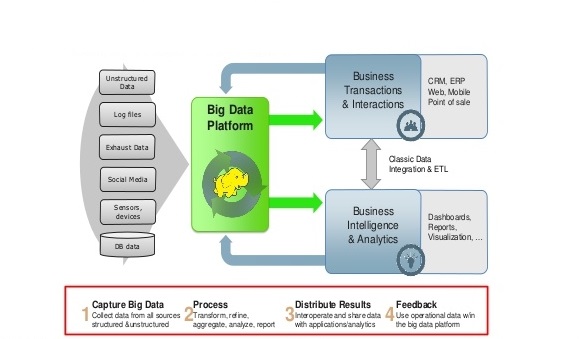
The Apache Hadoop is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single server to thousands of machines, each offering local computation and storage. Apache Hadoop is an open source software for affordable supercomputing; it provides the distributed file system and the parallel processing required to run a massive computing cluster. This learning path provides an explanation and demonstration of the most popular components in the Hadoop ecosystem. It defines and describes theory and architecture, while also providing instruction on installation, configuration, usage, and low-level use cases for the Hadoop ecosystem.
History of Hadoop ecosystem
In 2002, internet researchers just wanted a better search engine, and preferably one that was open-sourced. they called their project Nutch. In the year 2004, Google presented a new Map/Reduce algorithm designed for distributed computation. This evolved into MapReduce, a basic component of Hadoop. Google never implemented MR or GFS. Apache released the project in year 2005. In 2006, when Doug joined Yahoo!, he named the project after his son's toy elephant, and Hadoop was born. In 2007, Yahoo successfully tested Hadoop on a 1000 node cluster and start using it. It was a big thing in those days. Soon Facebook and the New York Times also started using Hadoop. In April 2008, Hadoop defeated supercomputers and became the fastest system on the planet by sorting an entire terabyte of data in just 68 seconds. Doug joined Cloudera in 2009. Cloudera is a sponsor of the Apache Software Foundation and is focused on enterprise-class deployments of the technology. In December of 2011, Apache Software Foundation released Apache Hadoop version 1.0. Hortonworks merged with Cloudera in January, 2019.
Three Basic Components of Hadoop Architecture
HDFS: Hadoop Distributed File System
HDFS is the primary component of Hadoop and is responsible for storing large data sets of structured or unstructured data across various nodes. HDFS is a fault-tolerant and self-healing distributed filesystem designed to turn a cluster of industry-standard servers into a massively scalable pool of storage. Developed specifically for large-scale data processing workloads where scalability, flexibility, and throughput are critical, HDFS accepts data in any format regardless of schema, optimizes for high-bandwidth streaming, and scales to proven deployments of 100PB and beyond.HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system's clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
YARN: Yet Another Resource Negotiator
The fundamental idea of YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons. The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job or a DAG of jobs.
The ResourceManager and the NodeManager form the data-computation framework. The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system. The NodeManager is the per-machine framework agent who is responsible for containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager/Scheduler.
The per-application ApplicationMaster is, in effect, a framework specific library and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the tasks.
The ResourceManager has two main components:
- The Scheduler is responsible for allocating resources to the various running applications subject to familiar constraints of capacities, queues etc. The Scheduler is pure scheduler in the sense that it performs no monitoring or tracking of status for the application
- The ApplicationsManager is responsible for accepting job-submissions, negotiating the first container for executing the application specific ApplicationMaster and provides the service for restarting the ApplicationMaster container on failure.
MapReduce: Programming based Data Processing
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
Typically the compute nodes and the storage nodes are the same, that is, the MapReduce framework and the Hadoop Distributed File System (see HDFS Architecture Guide) are running on the same set of nodes. This configuration allows the framework to effectively schedule tasks on the nodes where data is already present, resulting in very high aggregate bandwidth across the cluster.
The MapReduce framework consists of a single master ResourceManager, one worker NodeManager per cluster-node, and MRAppMaster per application.
Minimally, applications specify the input/output locations and supply map and reduce functions via implementations of appropriate interfaces and/or abstract-classes. These, and other job parameters, comprise the job configuration.