What is Data Mining
Data mining is the process of finding anomalies, patterns and correlations within large data sets to predict outcomes. Using a broad range of techniques, you can use this information to increase revenues, cut costs, improve customer relationships, reduce risks and more.Data mining is a cornerstone of analytics, helping you develop the models that can uncover connections within millions or billions of records.
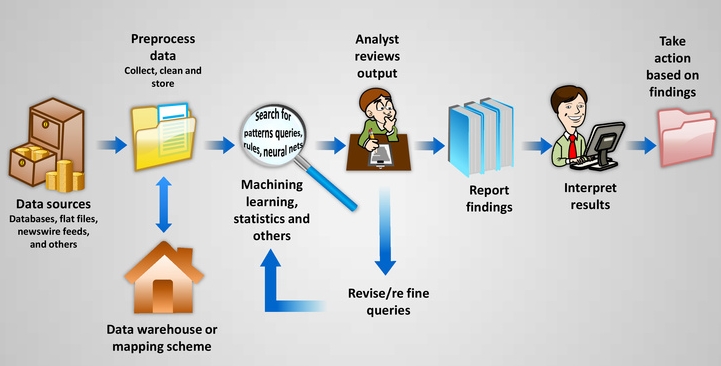
Data mining depends on effective data collection, warehousing, and computer processing.
The data sources can include databases, data warehouses, the web, and other information repositories or data that are streamed into the system dynamically.
Data Mining History & Current Advances
The process of digging through data to discover hidden connections and predict future trends has a long history. Sometimes referred to as "knowledge discovery in databases," the term "data mining" wasn't coined until the 1990s. But its foundation comprises three intertwined scientific disciplines, namely:
1.) Statistics
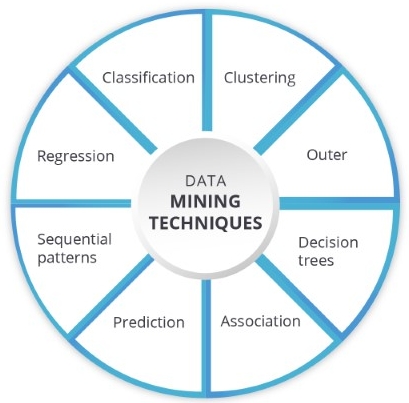
Statistics are the foundation of most technologies on which data mining is built, e.g. regression analysis, standard distribution, standard deviation, standard variance, discriminate analysis, cluster analysis, and confidence intervals. All of these are used to study data and data relationships.
2.) Artificial Intelligence
Artificial intelligence, or AI, which is built upon heuristics as opposed to statistics, attempts to apply human-thought-like processing to statistical problems. Certain AI concepts which were adopted by some high-end commercial products, such as query optimization modules for Relational Database Management Systems (RDBMS).
3.) Machine Learning
Machine learning is the union of statistics and AI. It could be considered an evolution of AI, because it blends AI heuristics with advanced statistical analysis. Machine learning attempts to let computer programs learn about the data they study, such that programs make different decisions based on the qualities of the studied data, using statistics for fundamental concepts, and adding more advanced AI heuristics and algorithms to achieve its goals.
What was old is new again, as data mining technology keeps evolving to keep pace with the limitless potential of big data and affordable computing power.
Why is data mining important?
So why is data mining important? You've seen the staggering numbers - the volume of data produced is doubling every two years. Unstructured data alone makes up 90 percent of the digital universe. But more information does not necessarily mean more knowledge.